Apple’s Director of Human-Centered Machine Intelligence and Responsibility, Jeffrey P. Bigham, at a 2024 Apple workshop — image credit: Apple
Apple Intelligence researchers have released a whole series of new academic papers concerned with furthering AI’s ability to be personalized and understanding how errors occur.
There is still this belief that Apple is behind the industry, but its researchers continue to publish papers that go far beyond Apple products and into the issues that affect all AI tools. The company’s research work extends back many years, but its latest papers have concentrated on AI flaws, and how to prevent unwanted AI actions.
Now its researchers have released eight new papers that chiefly extend this angle, and a whole series of videos from their presentations from Apple’s 2024 workshops on Human-Centered Machine Learning 2024.
Benchmarking AI and finding errors
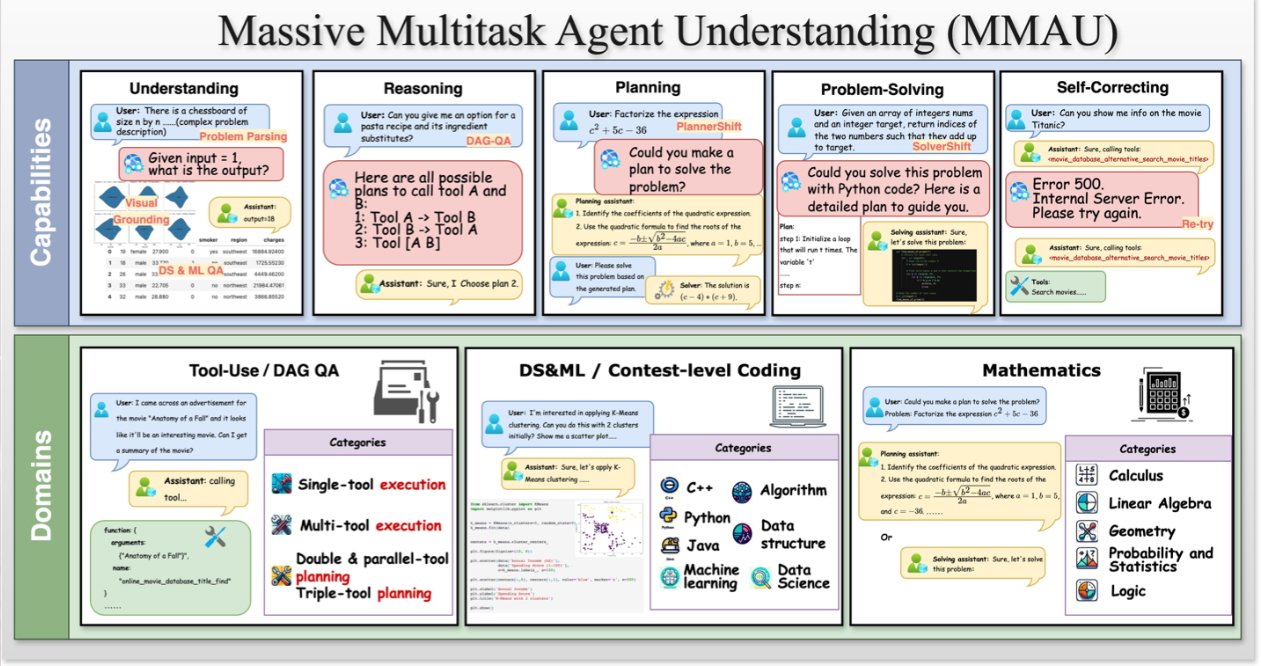
One of the new Apple papers proposes what its researchers call the Massive Multitask Agent Understanding (MMAU) benchmark. It’s a system of evaluating different Large Language Models (LLMs) across “five essential capabilities,” which are:
- Understanding
- Reasoning
- Planning
- Problem-solving
- Self-correction
Apple says that its MMAU benchmark consists of “20 meticulously designed tasks encompassing over 3K distinct prompts.” It’s claimed to be a comprehensive way of evaluating LLMs.
Detail from the paper showing a series of LLM evaluation processes — image credit: Apple
“Ultimately, MMAU not only sheds light on the capabilities and limitations of LLM agents but also enhances the interpretability of their performance,” continues Apple.
The purpose is to make improvements by understanding where errors originate, which Apple says is currently an issue because existing “evaluation methods blur the distinctions between different types of failures.” Its MMAU is also intended to be simpler to use than current alternatives.
This full paper can be read via Cornell University’s research paper archive.
Personalizing AI and learning from conversations
Apple suggests that AI LLMs are constrained by how they cannot be sufficiently personalized, such as to the extent that they remember previous conversations. The company says that up to now, attempts to personalize responses have concentrated on “incorporating small factoids” about the user’s preferences.
Instead, Apple proposes a system it calls the Pipeline for Learning User Conversations in Large Language Models, or PLUM. This “extracts question-answer pairs from conversations,” building up a method of “injecting knowledge of prior user conversations into the LLM.”
Read the full paper here.
External validation of LLMs and AI
LLMs can famously offer significantly different responses if a prompt is repeated with a different order of words, or just a longer or shorter version of the same. Apple describes this by saying that “AI annotators have been observed to be susceptible to a number of biases.”
However, Apple also argues that, presented with a response, humans have been persuaded “by responses’ assertiveness.” It’s the way that AI will proclaim its results as absolute and intractable fact, until you ask it again and it admits, no, none of it is true.
Detail from the external validation paper showing a methodology — image credit: Apple
So in a paper called “Can External Validation Tools Improve Annotation Quality for LLM-as-a-Judge?”, Apple wants to make better responses. It proposes doing so using “external validation tools based on web search and code execution.”
It notes, though, that in its research, this type of validation was only “often, but not always,” able to produce better results.
Read the full paper here.
Apple continues to present papers at AI events
Alongside research papers, Apple has also now published a series of eight videos from its 2024 # Human-Centered Machine Learning workshop. They range in length from 10 minutes to 38 minutes, and cover topics such as AI interfaces, and UI Understanding
The videos are all from sessions held in 2024, but Apple researchers are continuing to speak at new AI events. From July 27, 2025, to August 1, Apple will present new research at the annual Association for Computational Linguistics (ACL) in Vienna.
It’s presenting or sponsoring 18 workshops, many of which are based around its latest papers described here. Details of the Apple schedule at ACL are on Apple’s Machine Learning site.


{kind=link}